
Page 22 - 企業轉型腳步不停歇2022年數位優先世界成形
P. 22
20
此外Nvidia的NCCL和SHARP 技術被用來改善多GPU和多節點 的處理作業。NCCL利用現有的 頻寬和網路延遲來最佳化資料聚 合;SHARP則透過將CPU的運作 分攤至交換器,來免除不同端點 和伺服器間多次傳送資料的需要。 同時,更新版的MX網路配置,改 善了串接(concatenation)和區分 (split)等運作的所需的記憶體複 製效率。
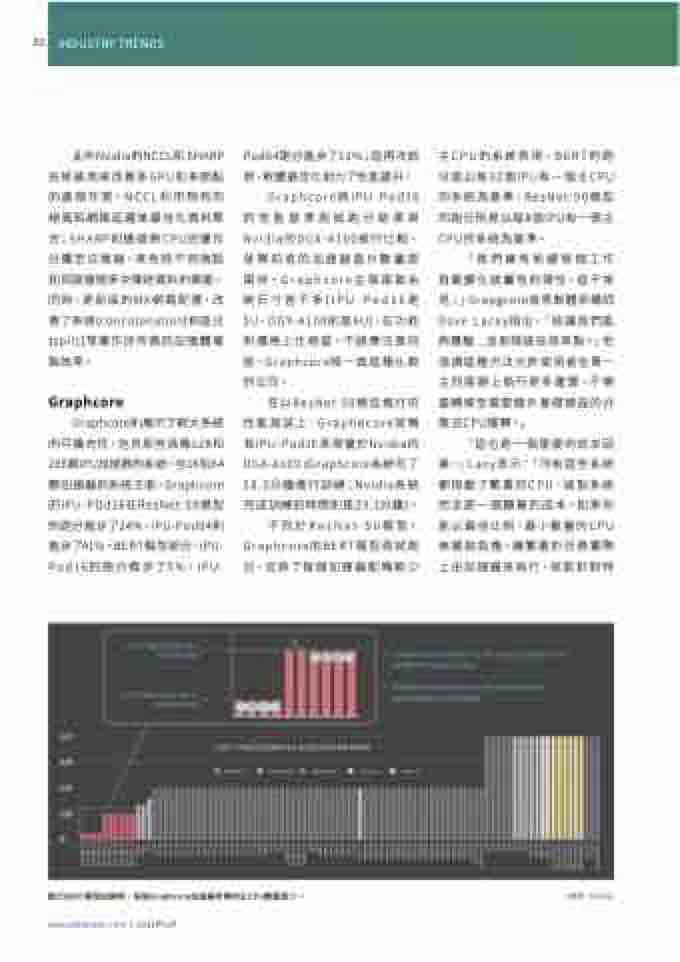
Graphcore則展示了較大系統 的可擴充性,包含那些具備128和 256顆IPU加速器的系統。在16和64 顆加速器的系統方面,Graphcore 的IPU-POd16在ResNet-50模型 的跑分進步了24%,IPU-Pod64則 進步了41%。BERT模型部分,IPU- Pod16的跑分進步了5%,IPU-
Pod64跑分進步了12%;這再次說 明,軟體最佳化助力了性能提升。
主CPU的系統表現。BERT的跑 分是以每32個IPU有一個主CPU 的系統為基準,ResNet-50模型 的跑分則是以每8個IPU有一個主 CPU的系統為基準。
Graphcore
Graphcore將IPU-Pod16 的性能基準測試跑分結果與 Nvidia的DGX-A100進行比較, 就算前者的加速器晶片數量是 兩倍。Graphcore主張兩套系 統尺寸差不多(IPU-Pod16是 5U,DGX-A100則是6U),在功耗 和價格上也相當。不過應注意的 是,Graphcore唯一做這種比較 的公司。
「我們擁有依據每個工作 負載變化該屬性的彈性,這不常 見;」Grapgcore首席軟體架構師 Dave Lacey指出,「這讓我們能 夠實驗...並取得這些效率點。」他 強調這種方法允許使用者在單一 主伺服器上執行更多運算,不需 要轉移至需要額外基礎建設的分 散式CPU運算。」
在以ResNet-50模型進行的 性能測試上,Graphecore宣稱 其IPU-Pod16表現優於Nvidia的 DGX-A100 (Graphcore系統花了 28.3分鐘進行訓練;Nvidia系統 完成訓練的時間則是29.1分鐘)。
「這也是一個重要的成本因 素,」Lacy表示:「所有這些系統 都搭載了繁重的CPU,這對系統 而言是一個顯著的成本。如果你 能以最佳比例、最小數量的CPU 來擺脫負擔,讓繁重的任務實際 上由加速器來執行,就能針對特
不同於ResNet-50模型, Graphcore的BERT模型測試跑 分,反映了每個加速器配備較少
進行BERT模型訓練時,每個Graphcore加速器所需的主CPU數量較少。
www.eettaiwan.com | 2022年1月
(來源:Nvidia)
INDUSTRY TRENDS
